➤ Introduction
This research aimed to investigate how implementing Low-Rank Adaptation (LoRA) alters the performance of SAM on segmentation of intracranial meningiomas in brain MRIs, compared to the baseline SAM performance. LoRA adds trainable layers parallel to existing model parameters, potentially enhancing performance without increasing inference latency. Our modified SAM that implements LoRA was dubbed SAM-LoRA. Such an approach was particularly significant as it offered a way to adapt large, pre-trained models like SAM to specialized tasks without the computational cost of full fine-tuning.
➤ Design and Implementation
LoRA layers were added to SAM's image encoder, keeping pre-trained parameters frozen while fine-tuning the new adapter layers. Various preprocessing techniques, including image slicing, centre cropping, and pixel value rescaling were implemented. The modified SAM was trained using the Adam optimizer, with performance evaluated using Dice scores and a combined Dice-Cross Entropy loss function.
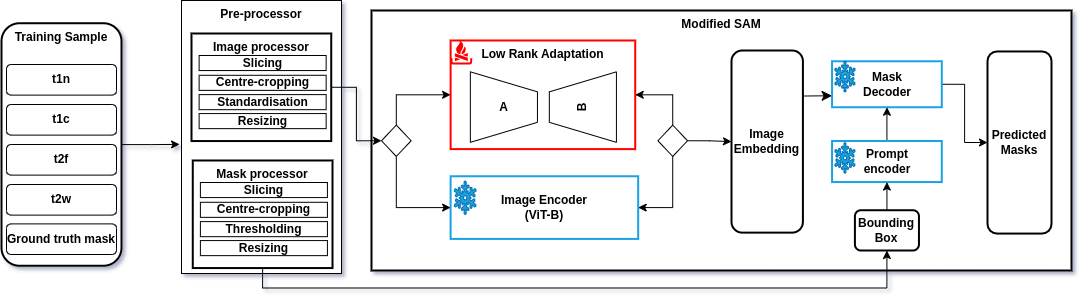
Figure 1: Modified SAM Architecture with LoRA Adapters
➤ Results and Discussion
The experiments compared the performance of SAM with different LoRA configurations (ranks 64, 128, and 256). LoRA_64 showed the lowest average losses, but all configurations displayed some unexpected patterns in training loss. A deeper analysis of LoRA_64 over 50 epochs showed initial improvements in both training and validation losses, followed by increasing losses after the 34th epoch. Dice score comparisons between the original SAM and LoRA-modified versions were inconclusive, with the LoRA models showing deteriorated performance.
The following accuracy trends were observed during model training:
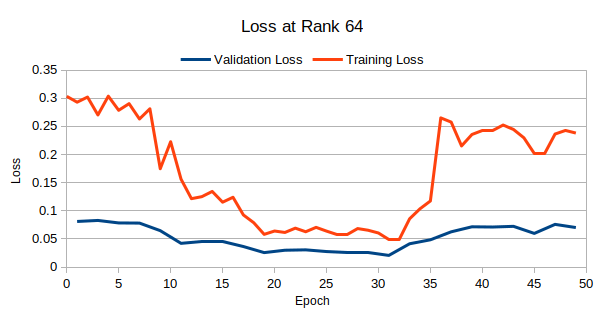
Figure 2: Training and Validation Losses for LoRA-64
Below are the predicted masks for LoRA-16, LoRA-32, and LoRA-64 models on sample 1100:



Reduction in training loss was not reflected in validation performance. Smaller ranks offered better performance but still fell below baselines. Visualisations of the predicted masks suggest the model is learning the entire image rather than tumour masks.
| Model | Accuracy | PEFT Comparison | Vanilla Comparison |
|---|---|---|---|
| LoRA-64 | 2.1% | -85.6% | -82.0% |
| LoRA-32 | 3.9% | -83.8% | -80.1% |
| LoRA-16 | 4.9% | -82.8% | -79.1% |
➤ Conclusions and Future Work
The study demonstrates that SAM modified with LoRA adapters can be trained for improved performance on tumor segmentation. However, reliable performance comparisons between the original SAM and LoRA-modified versions could not be established. Further experimentation with different adapter ranks and finer hyper-parameter tuning is needed to shed more light on the effectiveness of this approach for medical image segmentation.
For future work, we recommend further exploring different adapter configurations. Rather than adding adapters to the image encoder, adding them to the decoder or other parts of the model could yield better results. Related to this, the addition of adapters to fewer blocks of the image encoder could be explored.
Another area of interest is the level of freezing applied to pre-trained weights. The introduced adapters could be trained trained alongside the mask decoder to better adapt to the task. Investigating the impact of different pre-processing techniques and data augmentation strategies on model performance is also recommended.